
해시 (Hash)
Hash는 데이터를 저장하는 자료 구조 중 하나로, 특정한 함수를 사용하여 데이터를 일정한 크기의 고정된 값으로 변환하는 과정을 말합니다.
이렇게 변환된 값은 보통 “해시 코드” or “해시 값” 이라고 불립니다.
해시 함수는 임의의 크기의 데이터를 고정된 크기의 데이터로 변환하는 특징이 있습니다.
해시 함수(Hash Fuction)
해시 함수는 주어진 입력에 대해 항상 동일한 해시 코드를 생성하며, 입력 데이터가 조금만 다르더라도 해시 코드가 크게 달라져야 합니다. 이러한 특성을 가진 해시 함수를 “고르게 분포되었다” 고 말합니다.
해시 함수 종류
MD5, SHA-1, SHA-256 등 특정한 용도나 특성에 맞게 다양한 종류가 존재한다.
그 중 3가지 만 간략하게 설명하겠습니다.
1. MD5 (Message Digest Algorithm 5)
16바이트(128비트)의 해시 값을 생성
보안성이 낮고, 충돌에 취약
2. SHA-1 (Secure Hash Algorithm 1)
20바이트(160비트)의 해시 값을 생성
보안 측면에서 취약점이 발견되어 권장 하지 않음
3.SHA-256, SHA-384, SHA-512 등 (Secure Hash Algorithm)
SHA-2 계열은 각각 256, 284, 512 비트 등 다양한 해시 값을 생성
현재까지 안전하고 보안 강도가 높음
예) Java 에서는 ‘java.security.MessageDigest’ 클래스를 사용하여 다양한 해시 알고리즘을 적용할 수 있다.
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
public class HashFunctionExample {
public static void main(String[] args) {
String input = "Hello, Hash Function!";
try {
// MD5 해시
String md5Hash = hashString(input, "MD5");
System.out.println("MD5 Hash: " + md5Hash);
// SHA-1 해시
String sha1Hash = hashString(input, "SHA-1");
System.out.println("SHA-1 Hash: " + sha1Hash);
// SHA-256 해시
String sha256Hash = hashString(input, "SHA-256");
System.out.println("SHA-256 Hash: " + sha256Hash);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
}
private static String hashString(String input, String algorithm) throws NoSuchAlgorithmException {
MessageDigest digest = MessageDigest.getInstance(algorithm);
byte[] hashBytes = digest.digest(input.getBytes());
// Convert the byte array to a hexadecimal string
StringBuilder hexString = new StringBuilder();
for (byte hashByte : hashBytes) {
String hex = Integer.toHexString(0xff & hashByte);
if (hex.length() == 1) {
hexString.append('0');
}
hexString.append(hex);
}
return hexString.toString();
}
}
해시 함수를 사용한 자료구조
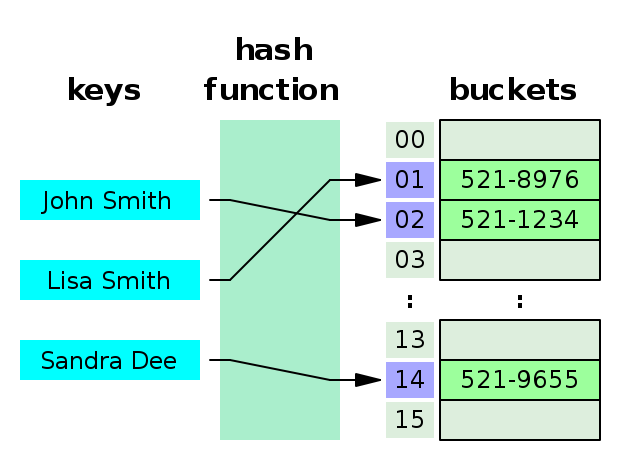
해시 테이블(Hash Table)
해시 테이블은 key와 value의 쌍을 저장하는 자료구조
key를 해시 함수를 통해 해시 코드로 변환하고 일정한 길이의 해시로 변경하고, 이를 배열의 인덱스로 사용하여 값을 저장하거나 조회합니다.
충돌이 발생할 경우에는 해결하는 방법으로는 체이닝(Chaining) 이나 개방 주소법(Open Addressing) 등이 사용됩니다.
데이터가 저장되는 곳을 bucket 또는 slot이라고 한다.
해시 테이블 장점
- 빠른 검색 및 삽입
- 해시 함수를 사용하여 고유한 해시 코드를 할당하므로, 특정 키에 대한 검색 및 삽입이 빠름
- 평균 시간 복잡도가 O(1)이지만, 충돌이 발생할 수 있어 시간 복잡도가 높아짐
- 평균 시간 복잡도가 O(1)은 입력 크기에 상관없이 알고리즘 수행 시간이 일정하다는 것을 의미하며 상수시간 내에 알고리즘이 실행된다고 말한다.
- 유연한 크기 조절
- 데이터 양의 따라 크기를 동적으로 조절
- 고유한 키값 쌍
- 키는 고유한 해시 코드를 가지므로 중복된 키를 허용하지 않음
- 효율적인 메모리 사용
- 충돌을 최소화 하고 효율적인 메모리 사용하도록 설계, 충돌 발생 시 체이닝 또는 개방 주소법으로 충돌을 처리
- 다양한 응용 분야 활용
- DB, 캐시 시스템, 인덱싱 구조, 집합, 맵 등 다양한 응용 분야에 활용
- 높은 성능
- 해시 함수와 충돌 처리 방법으로 높은 성능 제공
- 간편한 사용 및 구현
- 기본적인 연산(삽입, 삭제, 검색)이 간단 구현
HashTable 이해코드
import java.util.LinkedList;
class Entry<K, V> {
K key;
V value;
public Entry(K key, V value) {
this.key = key;
this.value = value;
}
}
public class HashTableExam<K, V> {
private static final int DEFAULT_CAPACITY = 10;
private LinkedList<Entry<K, V>>[] table;
private int size;
public HashTableExam() {
table = new LinkedList[DEFAULT_CAPACITY];
size = 0;
}
public static void main(String[] args) {
HashTableExam<String, Integer> hashTable = new HashTableExam<>();
hashTable.put("One", 1);
hashTable.put("Two", 2);
hashTable.put("Three", 3);
System.out.println("Value for key 'Two': " + hashTable.get("Two"));
hashTable.remove("One");
System.out.println("Value for key 'One' after removal: " + hashTable.get("One"));
// Value for key 'Two': 2
// Value for key 'One' after removal: null
}
private int hash(K key) {
return Math.abs(key.hashCode() % table.length);
}
public void put(K key, V value) {
int index = hash(key);
if (table[index] == null) {
table[index] = new LinkedList<>();
}
// 이미 존재하는 키인 경우 업데이트
for (Entry<K, V> entry : table[index]) {
if (entry.key.equals(key)) {
entry.value = value;
return;
}
}
// 존재하지 않는 경우 새로운 엔트리 추가
table[index].add(new Entry<>(key, value));
size++;
// 크기가 일정 수준 이상이면 배열 크기 확장
if (size > table.length * 0.75) {
resize();
}
}
public V get(K key) {
int index = hash(key);
if (table[index] != null) {
for (Entry<K, V> entry : table[index]) {
if (entry.key.equals(key)) {
return entry.value;
}
}
}
return null;
}
public void remove(K key) {
int index = hash(key);
if (table[index] != null) {
table[index].removeIf(entry -> entry.key.equals(key));
size--;
// 크기가 일정 수준 이하로 떨어지면 배열 크기 축소
if (size < table.length * 0.25 && table.length > DEFAULT_CAPACITY) {
resize();
}
}
}
private void resize() {
LinkedList<Entry<K, V>>[] oldTable = table;
table = new LinkedList[table.length * 2];
size = 0;
for (LinkedList<Entry<K, V>> bucket : oldTable) {
if (bucket != null) {
for (Entry<K, V> entry : bucket) {
put(entry.key, entry.value);
}
}
}
}
}예제로 HashTable에 대해 이해하기 쉽도록 클래스 와 메소드를 만들어 정의하였으나, java.util.Hashtable의 클래스의 메소드와 동일하게 동작
체이닝(Chaining)
bucket 또는 slot에서 충돌이 발생하면 기존 값과 새로운 값을 연결 리스트를 이용해 연결시키는 방법
체이닝 장점
- 유연한 메모리 사용 - 충돌시 공간 확보 및 한정된 저장소를 효율적으로 사용 가능
체이닝 단점
- 검색의 효율이 떨어짐 - 한 공간에 많은 연결로 인하여 다른 방면으로 메모리 사용이 많아짐
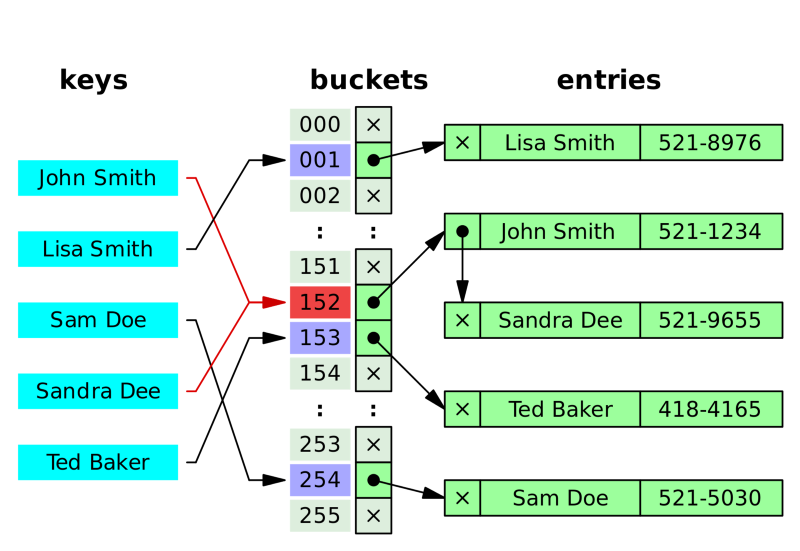
개방 주소법(Open Addressing)
해시 테이블에 충돌이 발생했을 때, 새로운 키-값 쌍을 위해 다른 빈 bucket을 찾아가는 방법이다.
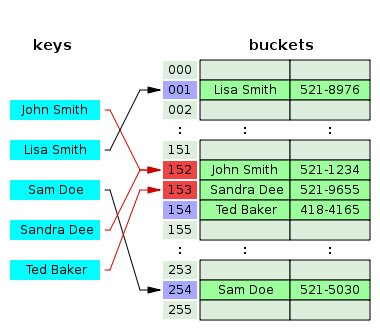
개방 주소법의 종류
1. 선형 탐사(Linear Probing)
- 충돌이 발생하면 다음 빈 버킷을 찾을 때까지 선형적으로 이동
- 예를 들어, 해시 값이 h인 버킷에서 충돌이 발생하면 h+1, h+2, h+3, … 순서로 빈 버킷을 찾아 이동합니다.
- 일정한 간격으로 이동하므로 클러스터링(Clustering) 현상이 발생
+클러스터링 현상
- 해시 테이블에서 충돌이 발생했을 때, 연속적인 영역에 데이터가 모여 있는 현상을 의미
- 충돌이 여러 번 발생하면 같은 해시 값에 해당하는 연속적인 버킷에 데이터가 밀집되어 저장되는데, 이러한 밀집 현상이 클러스터링이라고 함
2. 이차 탐사(Quadratic Probing)
- 충돌이 발생하면 이차 함수의 형태로 다음 빈 버킷을 찾아 이동
- 예를 들어, 해시 값이 h인 버킷에서 충돌이 발생하면 h+1^2, h-1^2, h+2^2, h-2^2, … 순서로 빈 버킷을 찾아 이동합니다.
- 선형 탐사 보다 클러스터링 현상을 완화 할 수 있다.
3. 이중 해싱(Double Hashing)
- 충돌이 발생하면 두 번째 해시 함수를 사용하여 다음 빈 버킷을 찾아나갑니다.
- 예를 들어, h1(k)를 기본 해시 함수, h2(k)를 충돌이 발생했을 때의 두번째 해시 함수라고 할때, 다음 빈 버킷을 찾을 때는 h1(k)+i * h2(k) 형태로 이동합니다.
- 이중 해싱은 클러스터링을 완화하고 충돌이 발생한 경우에도 효과적으로 빈 버킷을 찾을 수 있음
개방 주소법의 장점
- 메모리 효율 사용
- 적절한 충돌 해결 방법으로 성능 최적화
개방 주소법의 단점
- 클러스터링 현상 발생하여 성능 저하
- 시간 복잡도가 O(n)에 가까워짐 - 개방 주소법의 종류 방식으로 보임
해시 맵(Hash Map)
해시 맵은 해시 테이블을 기반으로 하며, 키-값 쌍을 저장하고 조회하는 자료구조
자바에서는 ‘HashMap’ 파이썬에서는 ‘dict’을 사용
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
// HashMap 생성
Map<String, Integer> hashMap = new HashMap<>();
// 데이터 추가
hashMap.put("Alice", 25);
hashMap.put("Bob", 30);
hashMap.put("Charlie", 22);
// 데이터 조회
System.out.println("Age of Bob: " + hashMap.get("Bob"));
// 데이터 업데이트
hashMap.put("Bob", 31);
System.out.println("Updated Age of Bob: " + hashMap.get("Bob"));
// 모든 데이터 출력
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue() + " years old");
}
}
}
해시 셋(Hash Set)
해시 셋은 해시 맵의 키만을 저장하는 자료구조로, 중복된 값이 존재하지 않음
import java.util.HashSet;
import java.util.Set;
public class HashSetExample {
public static void main(String[] args) {
// HashSet 생성
Set<String> hashSet = new HashSet<>();
// 데이터 추가
hashSet.add("Apple");
hashSet.add("Banana");
hashSet.add("Orange");
// 중복된 데이터 추가 (동일한 값을 중복으로 추가하면 무시됨)
hashSet.add("Apple");
// 데이터 조회
System.out.println("HashSet contains Orange: " + hashSet.contains("Orange"));
// 데이터 삭제
hashSet.remove("Banana");
// 모든 데이터 출력
System.out.println("Contents of HashSet:");
for (String fruit : hashSet) {
System.out.println(fruit);
}
}
}
블룸 필터(Bloom Filter)
해시 함수를 사용하여 원소의 존재 여부를 검사하는 자료구조로, 정확성보다는 공간 효율성에 중점을 둡니다.
정확도를 높이기 위해 일부 오류를 허용합니다.
그로인해 false positive가 발생하여 실제로는 데이터가 존재하지 않는데도 불구하고 해당 데이터가 존재한다고 잘못 판단하는 경우가 발생
발생하는 이유는 블룸 필터가 확률적인 자료구조 이며 고정된 크기의 비트 배열을 사용하는 데이터 표현하기 때문이다.
참고
[자료구조]해싱, 해시 테이블 그리고 Java HashMap
해시테이블은 해시함수를 사용하여 키를 해시값으로 매핑하고, 이 해시값을 색인 또는 주소 삼아 데이터(value)를 key와 함께 저장하는 자료구조이다.연관배열 구조: key와 value가 1:1로 연관되어있
velog.io
'코테 > 개념 정리' 카테고리의 다른 글
| 리스트 ArrayList <-> 배열 Array 변환 (1) | 2023.12.18 |
|---|---|
| 자료구조 - 스택(Stack) / 큐(Queue)에 관하여... (0) | 2023.12.09 |
| 제곱근과 합성수 간의 관계 (1) | 2023.12.01 |
| [Java]. 정수 오버플로우(overflow) (0) | 2023.11.30 |
| [Java]. BigInteger클래스 - 매우 큰 정수 표현 (0) | 2023.11.30 |